第一章 了解SQL
数据库概念
数据库是一种以某种有组织的方式存储的数据集合
主键的条件
第三章 使用MySQL
- 显示表列 show columns from 表名;(describe 表名)
- 自增 auto_increment
- 显示建表语句 show create table 表名;
- 显示建数据库语句 show create database 数据库名;
第四章 索引数据
- 去处重复 select DISTINCT 列名 from 表名
- DISTINCT作用于后面的所有列,使用了这个关键字除非后面的列都相等,否则会全部都索引出来。
- 限制结果 select 列名 from 表名 limit 5;
- 表示返回前5行
- 为了得出下一个五行 select 列名 from 表名 limit 5,5;
- 从第五行开始往后索引5条记录
第五章 排序索引数据
- 关系数据库设计理论认为,如果不能明确规定排序顺序,则不应该假定索引出的数据的顺序有意义。
- 数据排序 select 列名 from 表名 order by 列名;
- 在where关键字之后使用
- 可以使用非索引的列作为排序的依据
- 也可以用多个列作为排序的依据,按代码的顺序,来决定主次,如果主列中的值都是唯一的,则不会用次列的值排序
- 数据逆序排列 select 列名 from 表名 order by 列名 DESC;
- 在需要逆序排列的列名后加上DESC关键字
- 正序是ASC,是默认值
第六章 过滤数据
第七章 数据过滤
- 在where之后and的优先级比or要高,所以在多条件组合时要注意,尽量用括号来解决。
- IN ()用来指定条件范围,范围中的每个条件都可以进行匹配
- IN的优点
- 语法更清除直观
- 计算次序更容易管理
- IN操作符比OR操作符清单执行更快
- IN的可以包含其他select语句,能够动态的建立Where子句
- IN的优点
- NOT操作符否定之后所跟的任何条件
- MySQL支持对IN、BETWEEN、EXISTS子句取反
第八章 用通配符进行过滤
- % 表示任何字符出现任意次数(甚至是0次)
- 但是%通配符不能匹配null
- _ 表示任何字符出现一次
- 关于通配符的技巧
- 通配符会让搜索时间变长
- 不要过度使用通配符,如果其他操作可以达到相同的目的,就应该使用其他操作符
- 确实需要使用通配符时,除非绝对有必要,否则不要把它们用在搜索模式的开始处
- 仔细注意通配符的位置。如果放错地方,可能不会返回想要的数据
第九章 用正则表达式进行搜索
- MySQL正则表达式
- REGEXP 与 like用法一致,后面跟的是正则表达式
- MySQL中的正则表达式匹配不区分大小写,为区分大小写,可以使用BINARY关键字,如:where 列名 REGEXP BINARY ‘字符串’;
- 比起LIKE匹配整串而REGEXP匹配子串
- 正则表达式
- . 表示任意一个字符
- | 表示或
- [和] [123]表示1或2或3,可以理解为[1|2|3]
- 可以用^来取反 [^123]就匹配除这些字符以外的字符
- [0-9] 匹配数字0-9
- [a-z] 匹配所有的字母
- 当需要匹配特殊符号时 采用加\(两个反斜杠)的方式来区分\.表示.
- 下面的标示用来标示前面一个字符
- - : 表示0个或多个匹配 + : 表示1个或多个匹配 ? : 表示0个或1个匹配
- {n} : 指定数目的匹配 {n,} : 不少于指定数目的匹配 {n,m} : 匹配数目的范围(m不超过255)
- 可以用[0-9]{4}或者[[:digit:]]{4}来代表4个数字
- 定位符
- ^ : 文本的开始(在[和]集合中表示否定该集合)
- $ : 文本的结束
- [[:<:]] : 词的开始
- [[:>:]] : 词的结尾
- 通过^和$可以使REGEXP的作用类似于LIKE

第十章 创建计算字段
Concat(arg1,arg2,…)
- 这个函数在select后使用,可以将查询出来的数据以字符串的形式拼接起来 如: select Concat(名字, ‘ (‘, 城市, ‘)’)
RTrim()
- LTrim()去掉左边多余空格
- LTrim()去掉左边多余空格
- S 关键字用于起别名
- 可以在select语句后面对列进行算数运算,然后在用AS起个别名,客户机就可以像用其他列一样用这个列
第十一章 使用数据处理函数
常用文本处理函数


- SOUNDEX()
- 是一个将任何文本串转换为描述其语音表示的字母数字模式的算法
- 用于匹配发音类似的值
1
2
3select cust_name, cust_contact
FROM customers
where SOUNDEX(cust_contact)= SOUNDEX('Y.Lie')
日期处理函数
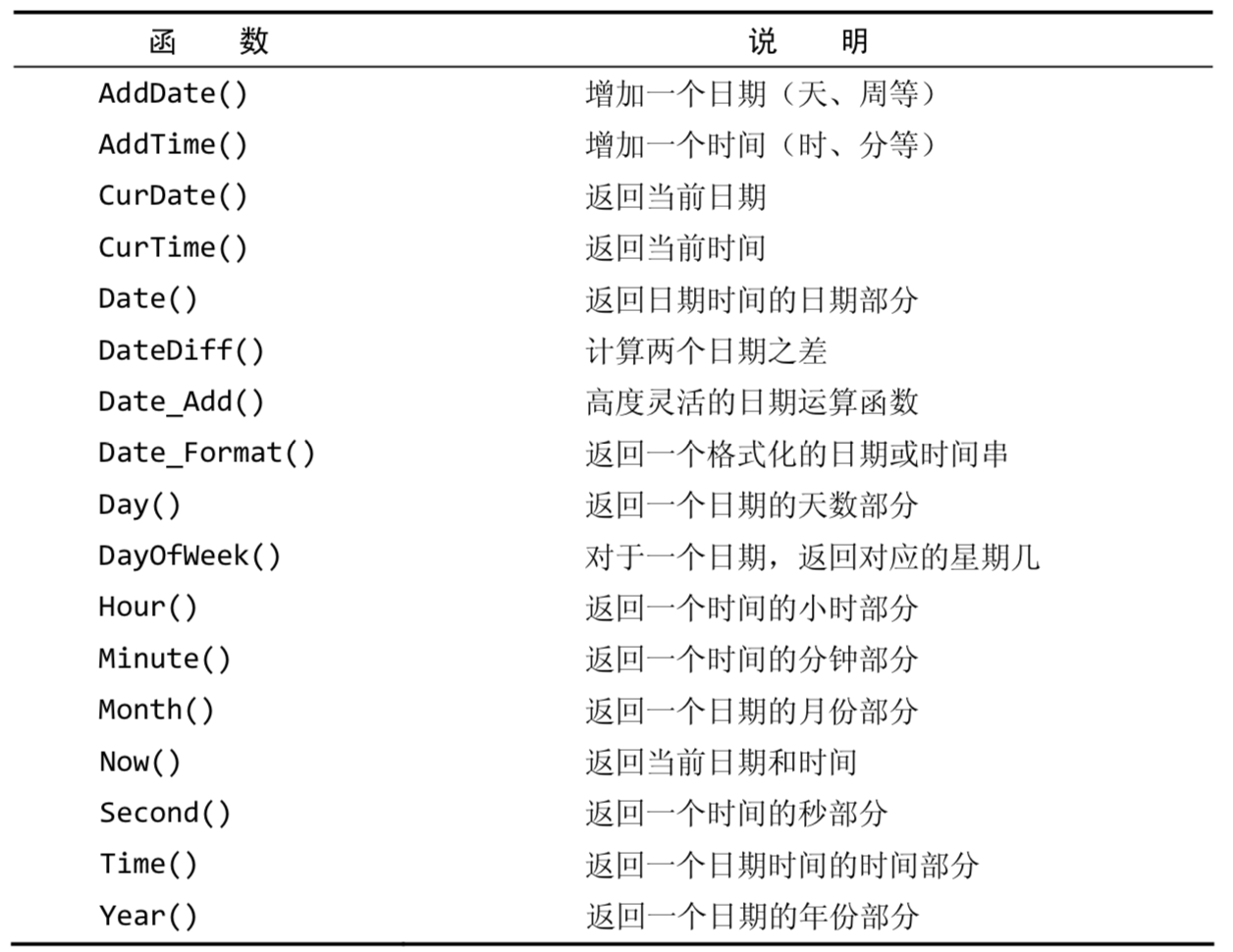
日期必须为yyyy-mm-dd格式
- 不过当你想要用日期和表中的日期相比较时,你应当使用Date()函数
- Date()函数指示MySQL仅提取日期部分,例:
1
2
3select cust_id, order_num
from orders
where Date(order_date) = '2005-09-01';
当你只想要时间时,可以使用Time()
- 如果你想检索出2005年9月下的所有订单,你可以用下面两种方法
第十二章 汇总数据
聚集函数

- AVG()函数
- 求平均值
- 忽略值为null的行
- COUNT()函数
- COUNT(*) : 返回总的行数,不管是列中是否为空(null)
- COUNT(column) : 有指定的列名时,指定列的值null的时候,被忽略
- 聚集不同值
- 使用DISTINCT关键字,比如说AVG(DISTINCT price),取平均值时,只考虑不同价格的。
- 使用DISTINCT关键字,必须使用列名不能用于计算或表达式
第十三章 分组数据
- 分组例子
1
2
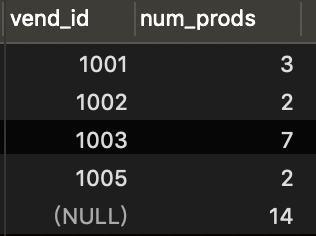
3select vend_id, count(*)
from products
group by vend_id;
GROUP BY
- 重要规定
- GROUP BY可以包含任意数量的列,使得能对分组进行嵌套,为数据分组提供更细致的控制
- GROUP BY子句中嵌套了分组,数据将在最后规定的分组上进行汇总。就是说,在建立分组时,指定的所有列都一起计算
- GROUP BY子句中列出的每个列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在select中使用表达式,则必须在GROUP BY子句中指定相同的表达式。不能使用别名
- 除聚集计算语句外,select语句中的每个列都必须在GROUP BY子句中给出
- 如果愤怒中具有多个null值,则null将作为一个分组返回。如果有多个null,它们将分为一组
- GROUP BY子句必须出现在WHERE子句后,ORDER BY子句之前
- 使用ROLLUP
- 可以得到每个分组以及每个分组汇总级别(针对每个分组)的值
1
2
3select vend_id, count(*) as num_prods
FROM products
GROUP BY vend_id with ROLLUP
- 可以得到每个分组以及每个分组汇总级别(针对每个分组)的值
结果: